
パソコン用CPUを手がけるIntelがまたもや微細化の壁に阻まれた。最先端プロセスとして市場投入予定であった10nmの量産延期を再び発表したのだ。同社は従来、2年周期で製造プロセスを刷新する「Tick-Tock」モデルを推進していたが、微細化技術の難易度向上から16年を境にこれが破綻。現行の14nmプロセスが実に6世代にわたって延命化が図られるという「異常事態」となっている。
19年延期を正式アナウンス
同社は18年第1四半期(1~3月)決算発表にあわせ、18年後半の量産予定であった10nmプロセスの量産時期を19年に延期することを正式にアナウンスした。製造工程において歩留まり向上に時間がかかっており、再度の量産延期となった。
10nmはもともと、16年後半からの量産開始が予定されており、クライアントPC向け第7世代Core iプロセッサーから適用されるはずだった。しかし、R&Dや設備投資負担の増大、技術的ハードルの高さから量産導入を延期。直近の予定では18年後半が本格量産の開始時期とされていたが、これを19年に延期すると公表した。
同社では今回の延期理由について、歩留まり面の問題を挙げている。すでにその改善方法は特定しているものの、改善ペースが想定よりも遅れていることから、既存の14nm世代の延命化を引き続き進めることを決めた。
同社は現在、第8世代Core iシリーズとして「14nm+」を用いた「KabyLake Refresh」、「14nm++」を用いた「CoffeeLake」を量産中。この後に10nmを用いた「CannonLake」を市場投入する予定であったが、これを見送り新たに14nm世代の「WhiskeyLake」を投入する計画。10nmが本格的に適用されるのは、19年投入予定の「IceLake」世代からとなりそうだ。
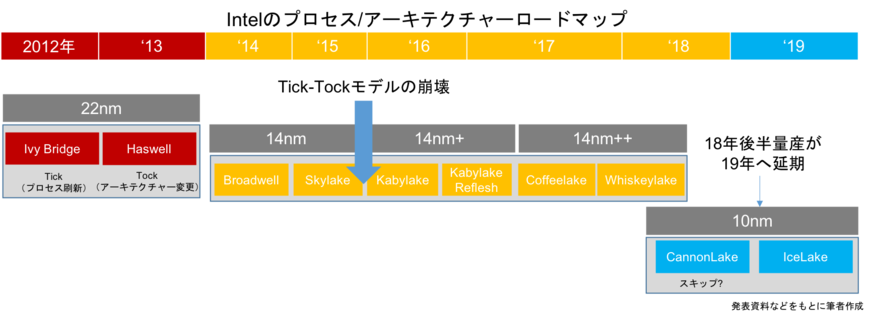
なお、同社では14nmの製造プロセス最適化やアーキテクチャーの改善などを通じて、最初の14nm世代に比べて最新の14nm世代はパフォーマンスが70%改善していると説明している。
同社は10nmの量産工場として、米オレゴン州の「D1D」、イスラエルの「Fab28」を予定していたが、今回の量産延期に伴い、Fab28の製造装置導入スケジュールが見直されたもようだ。
業界に渦巻く「Intel後退論」を払拭
半導体プロセスの微細化、とりわけロジックに関しては、これまでIntelが業界をリードするフロントランナーの立場にあった。しかし、近年はファンドリー最大手の台湾TSMCがプロセス微細化でIntelを猛追。「業界の盟主」という地位が揺らぎつつあった。しかも、半導体売上高に関しては17年にサムスン電子に抜かれ、20年以上守ってきた首位からも陥落した。
そんなIntelがまたもや量産延期を発表したことで、「Intel後退論」に拍車がかかっている印象だ。ライバルであるTSMCは18年から「7nm」と呼ぶ、最先端プロセスを量産開始予定で、見た目の数字上ではTSMCがIntelを抜いて微細化で業界をリードする趨勢にある。
こうした声に反論すべく、同社は17年4月に「Technology & Manufacturing Day」というアナリスト・投資家向けイベントを米国で開催している。Intelの肩を持つわけではないが、このイベント内容を理解すれば、必ずしもIntelがTSMCに微細化でビハインドしているとは言えない。むしろIntelはTSMC以上に難易度の高いことをクリアして、微細化を成し遂げようとしていることがわかる。
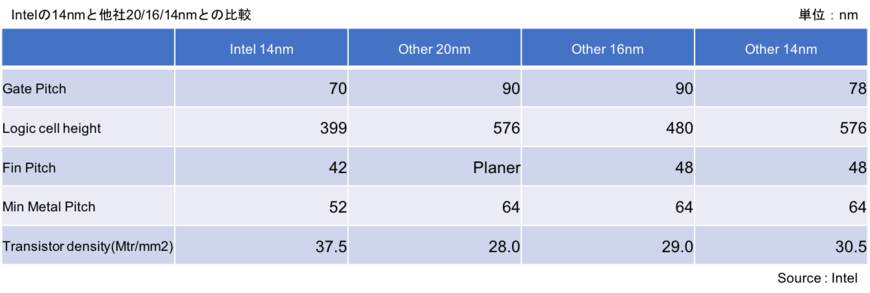
まず、現行の14nmについては競合他社の20/16/14nmに比べてトランジスタ密度は1.3倍の高密度化を実現できていると強調。また、Intelは14nmを14年に導入したのに対し、TSMCやサムスンなど競合の16/14nmの導入時期は15年以降と、微細化で1年以上先行しているとした。さらに、自社の14nmは3年後に出てきた他社の10nmと同等の集積度を実現していることも付け加えている。
2/2
10nmから新コンセプトを導入
同社は長年ムーアの法則に沿った半導体のスケーリングを実施してきたが、これを達成すべく14nm、次世代の10nmにおいては新たに「Hyper Scaling(ハイパースケーリング)」と呼ぶコンセプトを導入している。新ノードの導入サイクルは長期化するものの、ハイパースケーリングの導入によって、トランジスタの高密度化は加速させることができるという。また、同時に微細化で重要な性能向上とコストダウンを引き続き実現できることも同コンセプトのメリットだとしている。
ハイパースケーリングの具体的な事例として、同社ではメタル層のパターニング技術を挙げている。他社では同工程のパターニングにLELE(Litho-Etch-Litho-Etch)を用いているのに対して、インテルではSADP(Self Aligned Double Patterning)を採用している。同社によれば、LELEはパターニング間のミスアライメントで歩留まりとパフォーマンスにリスクを抱えているほか、コスト高になりがちだという。Intelが採用するSADPは80~40nmピッチまで対応可能だが、LELEは60nmまでしか対応できず、60nm以降はLELELEを用いる必要があるとしている。
ハイパースケーリングの導入に伴い、世代交代時に従来は0.62倍のスケーリング(ダイサイズ比較)であったものが、22nmから14nmは0.43倍、14nmから10nmへの微細化も0.43倍のスケーリングを達成できていると主張する。
14nmに比べて、フィンピッチは0.81倍、メタルピッチは0.69倍などを実現しており、メタル層には業界では初めてSAQP(self Aligned Quad Patterning)を導入。さらに、Single Dummy GateやContact Over Active Viaなどの新技術の採用によってトランジスタ密度は2.7倍を実現しているという。さらに、14nm世代同様に、10nmについても10+/10++といったかたちで機能拡張を行っていく計画だ。
ArF液浸+マルチパターニングが裏目に
ちなみに、メタルピッチ間隔でいえば、Intelの10nmとTSMCの7nmは同等サイズと見られている。IntelがArF液浸+SAQPという多重露光技術を使うのに対し、TSMCはEUV(18年の7nmはEUVを使わない)を使おうとしており、乗り越えるべきハードルはIntelの方が高い。EUVはスループットの問題などがあるものの、基本的にはシングルパターニングであるため、プロセス的にはシンプルだ。Intelも今回の10nm遅延の理由について、EUVを使わず、ArF液浸によるマルチパターニングを採用していることに問題があるとコメントしている。
また、今回の量産延期について、あえて量産時期を遅らせていると見る向きもある。現行の14nm世代は過去数年にわたって最適化されており、利益率が非常に高いのだという。まだまだ万全とはいえない10nmをリリースして収益性を下げるよりも、14nmを延命化させていった方がよいと判断している可能性も高そうだ。
問われる微細化の意義
微細化は本来、性能向上と同時にコストダウンも図れる手法として、これまで長年半導体産業の成長を支えてきた。コストが下がらず、むしろ上がるようなことになれば、微細化の意義は失われてしまい、新たな方向性を見出さなければならない。NANDフラッシュは3D-NANDという新手法によって新たな道を切り開いたが、ロジックとDRAMについてはまだ暗中模索という状況だ。
Intelが10nmという次世代プロセスをどう位置づけて、どのタイミングで量産に入ってくるのか、半導体産業の新たな方向性を示すうえでも大きな指標となりそうだ。
(稲葉雅巳)
電子デバイス産業新聞 副編集長 稲葉 雅巳

