背景には「平均値」のカラクリがあります。平均値とは改めて言うまでもなく、データの値の合計をデータの数で割ったものです。一見、ボリュームゾーンの数値が出るように思いますが、そうとは限りません。
というのは、突出して大きかったり小さかったりするデータがあると、平均値もその影響を受けるからです。
たとえば、極端な例として、「貯蓄0円」の人が99人、「貯蓄10億円」の人が1人という集団があった場合、平均値はいくらになるでしょうか。「10億円÷100」で1,000万円になります。だからといって「ここにいる100人の1人あたりの平均貯蓄は1,000万円です」と言われてもピンときません。
さらに、データの偏りもあります。調査の母集団の分布について、真ん中が盛り上がって左右が山の裾野のように低くなっている図を見たことがあるかもしれません。
ところが、貯蓄の現在高に関する世帯分布は、下の図のように、貯蓄が低い世帯のほうにかなり偏っています。2人以上の世帯について貯蓄現在高階級別の世帯分布を見ると、平均値(1,820万円)を下回る世帯が67.7%と約3分の2を占めています。
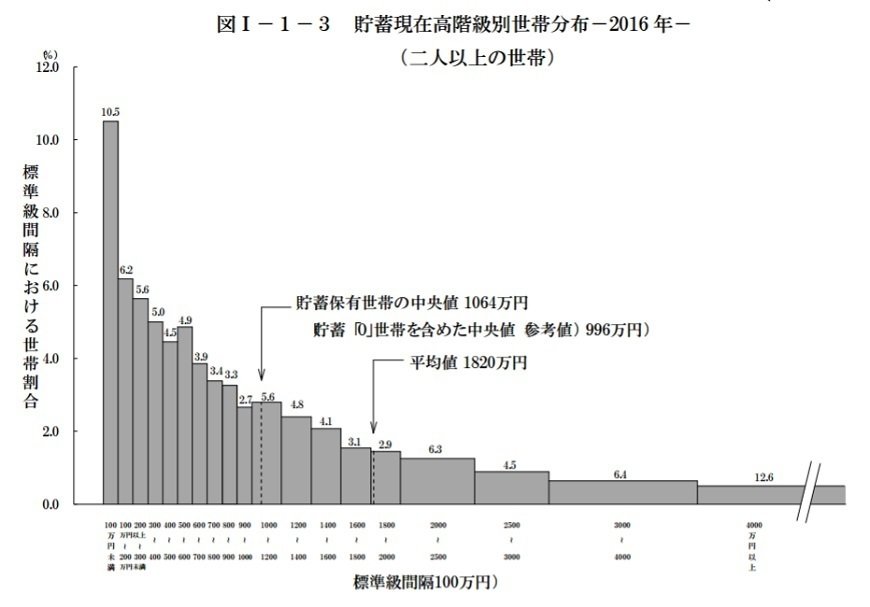
ちなみに、データ群の特徴を見る数値として、平均値以外に、中央値、最頻値などもあります。
中央値とは、データを大きい順(あるいは小さい順)に並べたときに、真ん中に来る値です(ボリュームゾーンではありません)。今回の調査の中央値は1,064万円で、貯蓄「0」世帯を含めた中央値は996万円となっています。
最頻値とは文字どおり、データの中でもっとも頻度が高いところです。先ほどの図のように、最頻値は「貯蓄100万円以下」の階級で、全体の10.5%を占めています。
年齢が高くなるほど貯蓄現在高が増える世代間の格差がある
平均値(1,820万円)を下回る世帯が約3分の2を占めていると紹介しました。では、平均値を引き上げている3分の1の世帯はどのような層なのでしょうか。ベンチャー企業の経営者のような一部の富裕層でしょうか。

